New Group Takes On Massive Computing Needs of Big Data
The sheer number of observations now streaming from land, sea, air and space has outpaced the ability of most computers to process it. The Data Science Institute’s newest working group —Frontiers in Computing Systems—will try to address some of the bottlenecks facing scientists working with these and other massive data sets.
(This story originally appeared on the website of the Columbia University Data Science Institute.)

In the big data era, the modern computer is showing signs of age. The sheer number of observations now streaming from land, sea, air and space has outpaced the ability of most computers to process it. As the United States races to develop an “exascale” machine up to the task, a group of engineers and scientists at Columbia have teamed up to pursue solutions of their own.
The Data Science Institute’s newest working group—Frontiers in Computing Systems—will try to address some of the bottlenecks facing scientists working with massive data sets at Columbia and beyond. From astronomy and neuroscience, to civil engineering and genomics, major obstacles stand in the way of processing, analyzing and storing all this data.
“We don’t have two years to process the data,” said Ryan Abernathey, a physical oceanographer at Columbia’s Lamont-Doherty Earth Observatory. “We’d like to do it in two minutes.”
Launched by computer science professor Steven Nowick, the initiative will combine researchers designing and analyzing extreme-scale computing systems for Big Data, and those working with massive data sets to solve ambitious problems in the physical sciences, medicine and engineering.
Scientists on the application side include Mark Cane, a climate scientist at Lamont-Doherty who helped build the first model to predict an El Niño cycle, and Rafael Yuste, a neuroscientist whose ideas on mapping the brain helped inspire President Obama’s BRAIN Initiative. In all, 30 Columbia researchers are involved.
Frontiers in Computing Systems will complement the institute’s s centers on automated data gathering, Sense, Collect and Move Data, and algorithms and machine learning theory, Foundations of Data Science. Approved by the institute’s board in June, Frontiers received letters of support from corporate and government leaders in high-performance computing and data analytics, including IBM, Intel and NASA’s Jet Propulsion Laboratory.
“This is a timely and interesting initiative, which promises to attack the underlying ‘systems’ aspects of Big Data, which in our view is absolutely essential,” wrote Dharmendra Modha, IBM’s chief scientist for brain-inspired computing, who led the development of IBM’s TrueNorth chip.
The initiative comes as the U.S. tries to reclaim its lead in high-performance computing. This year, China emerged as the world’s top supercomputing power, with 167 computers on a global list of top 500 machines. The race to develop a next-generation exascale machine, one thousand times faster than today’s leading petascale machines, has led to a surge of U.S. government support.
Last summer, President Obama signed an executive order creating a national strategic computing initiative to coordinate supercomputing research among federal agencies and advance broad societal needs. The U.S. Department of Energy has also created its own exascale initiative.

Energy and speed remain the key obstacles, whether building centralized supercomputers and data centers, or networks of smaller systems connected by wireless.
To perform at least a billion billion operations per second, these exascale systems need to radically cut energy use. To get there, engineers are rethinking traditional von Neumann architecture, which separates data storage from processing, as well as developing entirely new computing paradigms.
Several promising directions have emerged. Under one, computers mimic the brain with circuits designed to store and process information the way neurons and synapses do. This lets chips run massive numbers of tasks in parallel while conserving energy. Using this approach, IBM’s TrueNorth chip requires less than 100 milliwatts to run more than 5 billion transistors, compared to modern processors which need more energy to power far fewer transistors.
A second approach is designing customized, high-performance computer architectures for specialized tasks. From hardware to software, the Anton supercomputers developed by D.E. Shaw Research, a research institute in New York, are designed to simulate protein dynamics, important in drug-discovery and understanding basic cell processes.
At Columbia, researchers are exploring both directions and more.
Nowick, the working group’s founder, is tackling the daunting communication challenge facing next-generation chips. He and his lab are developing “networks-on-chip,” to organize the complex data flows from hundreds of processors and memory stores running at wildly different rates. By eliminating the central organizing clock of traditional chips, their designs allow components to be easily assembled, Lego-like, and upgraded to provide more processing power and memory.
In related work, computer scientist Luca Carloni and his lab are developing tools to design and program “system-on-chip” computing platforms embedded in everything from smartphones to cars to data centers. With hardware customized for specific applications, these single-chip platforms can execute tasks far more efficiently than software running on conventional processors. Other group members are developing brain-computer interfaces, chips for medical devices, and customized computers to solve differential equations for scientific applications.
The working group is also focused on adapting software and databases to big data applications. Computer scientist Roxana Geambasu is designing tools that allow developers to write and optimize programs for large-scale machine learning problems. Computer scientist Eugene Wu is creating interactive database systems to help users visualize and analyze their results.
Neuroscientists in the group will also contribute. Their insights into brain structure and function could lead to important advances in computer software and hardware. Conversely, the neuroscientists hope to gain new ideas for modeling the brain from interactions with computer systems researchers.
“When you get engineers and scientists together, exciting ideas emerge,” said Nowick, chairman of the working group. “Many of the breakthroughs in extreme-scale computing are expected to happen as systems designers come to understand the unique needs of researchers grappling with big data sets.”
Those researchers span many fields. In materials science, the problems involve solving equations from quantum mechanics to explain why a material behaves the way it does. Behind these epic math problems are extremely practical applications.
Applied physicist Chris Marianetti, vice chair of the new working group, is trying to understand how lithium atoms pass in and out of a material, one of the secrets to designing a longer-lasting lithium battery. But computational limits have stymied him on this problem and others. “We can burn through as much computing time as we’re given,” he said. “Materials scientists are notorious. You don’t want to be sharing computer time with us.”
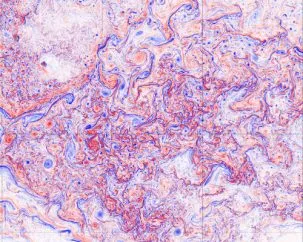
In medicine, the rise of electronic health records is helping researchers to study disease at unprecedented scale, but here, too, computational challenges remain. Nicholas Tatonetti, a biomedical researcher at Columbia University Medical Center, has mined data from more than a million patients to uncover dangerous side effects when combinations of drugs are taken together. However, the ability to scale this work depends on further breakthroughs in parallel computing and database design.
For now, Columbia researchers crunch their data on federal supercomputers or the university’s high performance computing system. Such massively parallel systems are optimized for modeling weather and climate, for example, but are not well suited for complex big data problems.
At Lamont-Doherty, Abernathey has explored NASA’s new groundbreaking simulation of ocean waves interacting with large-scale currents, run on NASA’s Pleiades supercomputer. He would like to analyze the petabytes of data the simulation has generated, but lacks the processing power to do so.
“These models now output so much data it’s impossible to understand what they’re doing,” he said.
Columbia’s Lamont-Doherty Earth Observatory and Earth Institute, and the NASA Goddard Institute for Space Studies are among the institutions represented in the new working group.
The group aims to attract funding from the U.S. government and industry. In addition to IBM, NASA’s JPL and Intel, the group received letters of support from senior scientists and managers at Sandia National Laboratories, Microsoft Research, NVIDIA and D.E. Shaw Research. If all goes as planned, the working group will become a full-fledged institute center in the next year, said Nowick.
Kim Martineau is assistant director for strategic communications and media relations at Columbia University’s Data Science Institute, and a former science writer at the Lamont-Doherty Earth Observatory.
Save
Save
Save
Save
Save
Save
Save
Save